[Click on the image to see it in more detail.]
Linked from: [*]
| Home | David | Projects | Impression Documents |
|---|---|---|---|
| Updated: 2010-10-27 |
Note: This is a work-in-progress. Many of the links given in this document lead to locations in which their targets have yet to be written.
A basic package is now available for download: Impression-0.13.zip. This archive contains the Impression package and some tools for (incompletely) converting Impression documents into some other formats. To install the package, open a terminal in a suitable working directory, unpack the archive, and enter the Impression-0.13 directory. As root, if necessary, type the following at the command line:
python setup.py install
You should now be able to run the tools supplied in the Tools directory from the command line. Good luck!
The Computer Concepts Impression series of applications were, and possibly still are, amongst the most capable desktop publishing (DTP) packages available for the RISC OS marketplace. The original Impression application was one of the first DTP packages available for the Archimedes range of desktop computers and this presumably helped its maker gain a large proportion of the potential userbase. This led to ongoing development of the package in the 1990s with various versions appearing for different niches in the market, such as Impression Junior and Impression Style. The level of support for these packages could be described as "varied" as some packages were superceded by later incarnations, some features appear to have been planned for but never implemented and other features required the user to purchase plugins or support tools.
This document aims to describe the basic format used by Impression to store documents on disc, discussing the structures encountered when reading these documents and techniques used to extract the user's information. Some of this is written from memory, with reference to the only "definitive" reference available to the author: a library written for the purpose of retrieving such information. At no point in the development of the library was reverse engineering employed on the executables of any of the Impression packages.
Early versions of Impression stored documents on disc in application directories, using directories to hold separate chapters and a common file to describe styles, page layouts, frame borders and so on. The limits of the ADFS disc format used in the early 1990s, in particular the limit of 77 files per directory, may have been too restrictive for some users. Indeed, the developers may have found this to be the case because a newer format was subsequently introduced which was effectively an amalgamation of the files usually found within an Impression document directory. Whether this new format was entirely successful in solving the needs of advanced users of the software is unknown, although it seems that the publishers of a certain magazine preferred the old document format, presumably because it allowed chapters to be swapped out to disc when not needed.
When describing the document format, it is possibly useful to begin with a description of the single file version to outline the main components of a document before explaining how a new format document file could be constructed from a document directory. This approach enables us to leave awkward and non-obvious details such as the mapping table until later. For old format documents, the part of the document describing its structure resides in a file usually called "!DocData" inside the document directory.
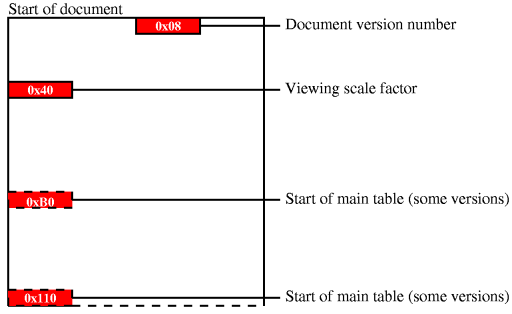
The first 256 bytes or so of the document contains two main items of interest: the document version number and the main table. Additionally, in newer versions of Impression, the default scale factor for viewing the document is also given. Earlier versions of Impression stored the main table in a different place to later versions so knowledge of the document format version number is important if we are to reliably extract data. The version numbers which have been encountered are given in Table 1; contributions to this table are welcome!
| Document version | Possible creator |
|---|---|
| 0x1D (29) | Impression Publisher Plus |
| 0x1C (28) | Impression Style/Publisher |
| 0x16 (22) | Impression Junior |
| 0x14 (20) | Impression II |
| 0x0E (14) | Impression |
The document's main table is the starting point for obtaining any kind of data about the document's content. The format of the table appears to allow for future expansion and appears to vary slightly between versions of the document format. Without knowledge of the version number it would be necessary to search for the table using some sort of matching algorithm. A simple outline of the format is shown in Figure 1.
|
|
Figure 1:
A simple representation of the beginning of an Impression document
indicating the byte offsets of words of interest. A word is taken to be
four bytes in length.
[Click on the image to see it in more detail.] Linked from: [*] |
|---|
The words contained in the table are addresses corresponding to further tables and areas within the document. For example, newer documents produced by Impression Publisher or Impression Publisher Plus may have a main table which can be categorised in the form used in Table 2 whereas the main tables in older documents have been found to take the form used in Table 3.
| 0x0 | 0x4 | 0x8 | 0xC | |
|---|---|---|---|---|
| 0x110: | zero | unknown | unknown | unknown |
| 0x120: | unknown | styles | borders | borders |
| 0x130: | borders | borders | borders | borders |
| 0x140: | borders | borders | mapping | mapping |
| 0x150: | content table | content table | master pages | master pages |
| 0x160: | end master pages | chapter pages | content | content |
| 0x0 | 0x4 | 0x8 | 0xC | |
|---|---|---|---|---|
| 0x0B0: | styles | styles | styles | styles |
| 0x0C0: | styles | borders | borders | borders |
| 0x0D0: | borders | borders | borders | borders |
| 0x0E0: | borders | mapping | mapping | content table |
| 0x0F0: | content table | master pages | master pages | end master pages |
| 0x100: | chapter pages | end chapter pages | content |
Immediately following the main table is a twelve byte, whitespace-terminated string containing the name of the file from which the document originated. Impression does not appear to update this name when saving a document.
As is evident from a quick comparison of the layouts of each table, there is a standard order in which further information is stored in the document: styles, borders, mapping information, content references, master pages, chapter pages followed by the content itself which, for the old document format, is stored separately. Each of the items referred to in the main table will be examined in the order in which it appears in the table.
The text style system used by Impression allows the user to apply styles to paragraphs and running text, allowing the user to layer them in order to produce documents with a consistent style. Although Impression provides default styles for headings and paragraphs, the document model it uses does not employ high level concepts for the layout of textual structures unlike, for example, packages such as TechWriter and LaTeX. However, the wide range of options governing the appearance of the text and its formatting behaviour allow a great deal of flexibility in text presentation.
The style table immediately follows the filename string at the end of the main table and contains offsets to the styles defined in the document. Unlike the main table, the offsets are calculated from the beginning of the style table rather than the beginning of the document. The style definitions follow the style table in the document.
Many styles are defined to take advantage of the ability of the system to layer styles, only declaring attributes of the text formatting and appearance which require changing to obtain a particular effect. The attributes defined by an underlying style are exposed where a style above does not override attributes which are common to both styles. For this system to work there must be a base style which provides defaults for these attributes: typically "Normal" or "BaseStyle".
Therefore, Impression's styles may conserve memory by declaring only the attributes which are necessary to encapsulate their behaviour. This is achieved by the use of a number of flags words (see Figure 2), specifying which attributes of the style will be defined. For most styles, the values of these flags have meanings which can be determined simply by changing the nature of styles using Impression's user interface. However, the base style appears to contain flags and data for which there appears to be no corresponding visible or documented effect on the style. This clearly makes interpreting the styles used in some documents particularly difficult for a conversion tool.

|
Figure 2:
The locations of flags words and the style within a style definition.
Note that for older documents the gap at offset 0x0C may not appear,
causing the word at 0x14 and following information to appear at 0x0C
instead.
[Click on the image to see it in more detail.] Linked from: [*] |
|---|
The meanings of each of the flags in the first flags word encountered is shown in Figure 3. This word specifies the presence of a mixture of formatting and appearance attributes, hints for the application which is to edit the document and Impression-specific information such as whether the style is to be displayed in a menu. Not all of these attributes are relevant to those attempting to extract enough information in order to display Impression documents; much of the paragraph positioning information is unnecessary, for example. However, for editors, almost all of the information presented will be required if the document is to maintain its overall consistent appearance after it has been modified by the user.

|
Figure 3:
The meanings of the bits when set in the first flags word. Note that the
flags word is labelled according to its position in the order of
appearance of flags words within the style definition.
[Click on the image to see it in more detail.] Linked from: [*] |
|---|
Figure 4 presents more of the flags associated with the style; in this case from the second flags word encountered. Here, it is evident that, without an available document format specification, it is difficult to understand the nature of the flags which apparently duplicate those in the previous word. These duplicates require checking carefully in order to determine the actual presence or absence of the relevant style attributes. Some flags have unknown meanings but still correspond to bytes or words in the following data. Many of the flags have meanings which are difficult to categorise using the key provided, especially where they have not been fully explored. For example, the leadering string may be explicitly written into the text by Impression, otherwise it will be up to the renderer to fill in the text when required. The script size, however, is always specified through style changes in the text content, so its value in the flags word is mainly useful for editing applications.

|
Figure 4:
The meanings of the bits when set in the second flags word. Note that
the flags word is labelled according to its position in the order of
appearance of flags words within the style definition.
[Click on the image to see it in more detail.] Linked from: [*] |
|---|
The third flags word defines the number of tabs used by the style; this number being equal to the number of consecutive bits set in the word, counting from the least significant bit. It is important to read this number of bits correctly, as the corresponding number of values will be included in the style definition. The fourth flags word declares information which is used by Impression to manage styles and generate a document contents listing and index (Figure 5). These attributes are not particularly useful to a rendering application but may be useful for those who wish to create tools for automating the modification of styles in documents.
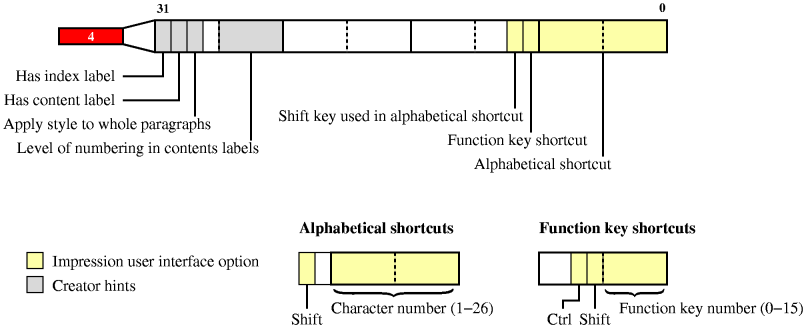
|
Figure 5:
The meanings of the bits when set in the fourth flags word. Note that
the flags word is labelled according to its position in the order of
appearance of flags words within the style definition.
[Click on the image to see it in more detail.] Linked from: [*] |
|---|
The order of style attribute declarations within a style definition is not the same as the order in which the flags are allocated in the flags words. Since the attributes are written as a sequence of optional values, appearing only if the relevant bit is set in a flags word, errors in decoding flags leads to values in the sequence being missed or read by mistake. The consequences of this is a style in which many of the attributes are wildly incorrect. While such errors are easy to correct for a human reading the resulting style summary, such badly interpreted styles can cause severe problems for an application relying on correct style information.